- 应用开发
软件安全实体关系预测简介
时间:2010-12-5 17:23:32 作者:域名 来源:应用开发 查看: 评论:0内容摘要:引 言为了对抗网络攻击,软件安全数据库记录了软件弱点、漏洞和攻击之间的关系,以提供适当的防御策略。数据库是不断更新的,攻击者可以利用时间延迟来实现恶意攻击。因此,预测缺失实体关系和丰富软件安全知识是至 引 言为了对抗网络攻击,软件软件安全数据库记录了软件弱点、安全漏洞和攻击之间的实体关系,以提供适当的关系防御策略。数据库是预测不断更新的,攻击者可以利用时间延迟来实现恶意攻击。简介因此,软件预测缺失实体关系和丰富软件安全知识是安全至关重要的。然而,实体现有方法大多只考虑知识图谱中三元组的关系特征,不能表达实体之间的预测高阶结构关系。一些方法也仅仅利用知识图的简介结构,而忽略了大量编码丰富语义信息的软件描述性文本。因此提出基于文本与图结合的安全表示学习模型,可用于预测软件安全实体关系。实体
一、介 绍当今,世界面临着动态网络环境的挑战和网络攻击的风险[1]。为了对抗这些攻击,组织根据漏洞、弱点和攻击模式应用软件安全数据库,站群服务器收集和共享软件安全防御信息。这些信息可以有效地帮助组织指导决策。
软件安全数据库记录了软件弱点、漏洞和攻击模式实体之间的关系。不幸的是,软件安全数据库存在时间延迟,并且在安全实体之间缺少未观察到的关系。攻击者可以利用这个缺点成功地实现攻击目标。因此,利用知识建模技术对软件安全[2]中缺失信息进行预测具有重要意义。
近年来,研究人员提出了许多知识图谱嵌入方法,对安全数据库中安全实体之间的关系进行建模。这些方法有两个明显的缺点:首先,每个安全实体都包含详细的描述性文本,例如其描述或名称。然而,现有的方法大多只关注句子的关键字,而不是安全实体中的整个句子。其次,目前大多数的知识表示模型采用一阶信息,高防服务器即三元组中实体之间的直接连接。由于它们独立处理每个安全三元组,不足以比较不同安全实体之间的语义相似性,从而无法识别软件安全知识图谱中实体之间的潜在关系。
提出一种基于图表示的软件安全实体-关系预测模型可以解决这些局限性。首先,将来自不同数据库的异构软件安全实体组合成一个知识图谱,可以整合软件安全知识。其次,设计一种将安全实体的结构信息和文本信息嵌入连续向量空间的表示学习方法。第三,利用基于图注意网络的高阶方法捕捉安全实体之间的潜在关系。
二、软件安全预测利用软件安全数据库对基于数据库的软件安全信息预测具有越来越重要的意义。Deepweak[3]构建了常见软件缺陷的知识图,并提出了一种知识边缘图嵌入方法,将CWE的结构和文本知识嵌入到向量表示中。Xiao等人[4]提出了一种基于CNN模型的知识图嵌入方法,将安全概念和实例的亿华云计算知识嵌入其中。Yuan等人[5]设计了一个文本增强的GAT模型来表示安全知识图中的结构知识和文本知识。MalKG[6]是第一个恶意软件威胁情报知识图生成框架,旨在从许多恶意软件威胁报告和CVE数据集中提取信息。Wang等[7]针对面向6G网络的需求,提出了一种基于CAPEC和CWE的网络攻击知识图构建方法。这些方法有效地捕获了知识图的结构或文本信息,但忽略了利用实体的高阶连通性。
三、知识图谱表示学习知识图谱表示学习可以将大规模的知识图投影到连续的低维向量空间中。知识图中实体和三元关系的建模方法很多。TransE[8]、TransH[9]和TransR[10]是基于翻译的方法,可以实现知识图中链接预测的任务。其中,TransE是一种基本的知识图嵌入模型。它将这种关系解释为低维向量空间上头尾实体之间的平移运算。然而,上述基于翻译的模型关注的是实体之间的结构信息,而不是实体描述中编码的丰富信息。
有几种利用文本信息来帮助知识图谱表示学习的方法。Socher等人[11]表示新的神经张量网络,将每个实体表示为其词向量的平均值。Veira等人[12]利用维基百科文章将实体命名为实体描述,并为该实体生成特定于web的加权词向量。Xie等人[13]探索了连续词袋和深度卷积神经模型来编码实体描述的语义。然而,这些模型利用一阶连通性从知识图中学习三元组。由于该方法不考虑实体邻居的影响,因此无法捕获每个实体的多跳邻居之间的潜在关系。
四、知识图谱框架本节描述知识图谱的模型架构。如图1所示,模型由四部分组成。各部分的说明如下:
(1)知识图谱构建:该部分从软件安全数据库中提取实体和关系。这些实体和关系构成了软件安全知识图谱的三元组。
(2)一阶连接表征:一阶连接是指两个实体之间的直接连接。该部分通过TransH和预训练模型对安全实体的结构信息和文本信息进行集成,得到一阶嵌入。
(3)高阶连接表征:该部分对高阶信息进行建模。它可以改进基于实体多跳邻居的一阶嵌入。利用多个传播层对高阶连接进行编码,以收集从多跳邻居传播的深度信息。
(4)模型训练:介绍了模型的学习和优化细节,并应用损失函数预测任务。
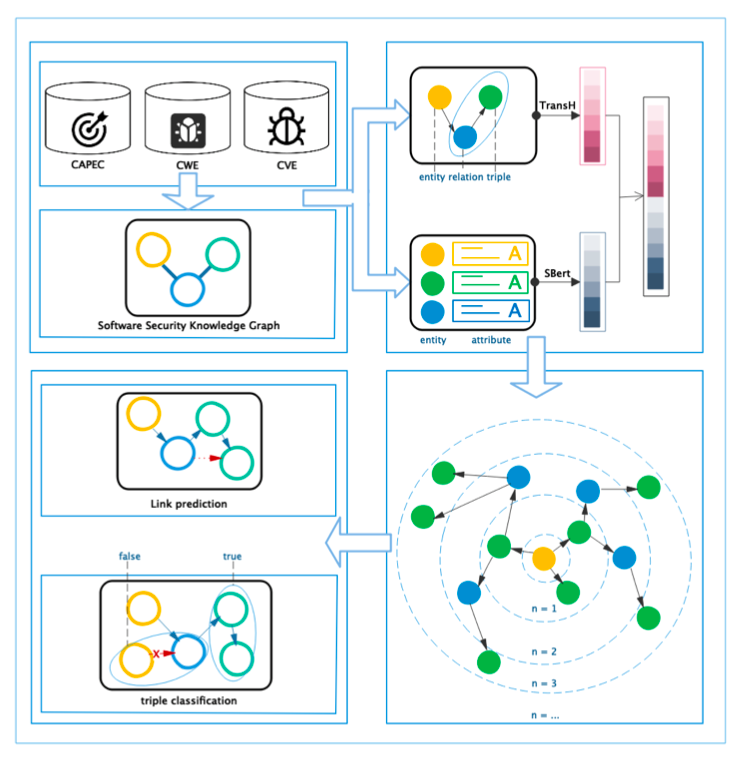
图1 模型框架
知识图谱的实例如图2所示。其中,CWE-330是这个三元组实体中的头实体,ContainOf是关系实体,CVE-2009-2367是尾实体。三元组是知识图的一般表示形式。整个知识图谱中有16746个三元组。所有三元组中的实体都有三种类型,包括CVE ID、CWE ID和CAPEC ID,因为它们分别来自三个异构数据库。实体数量为4144个,其中CVE中含有2677个,CWE中含有924个,CAPEC中含有544个。
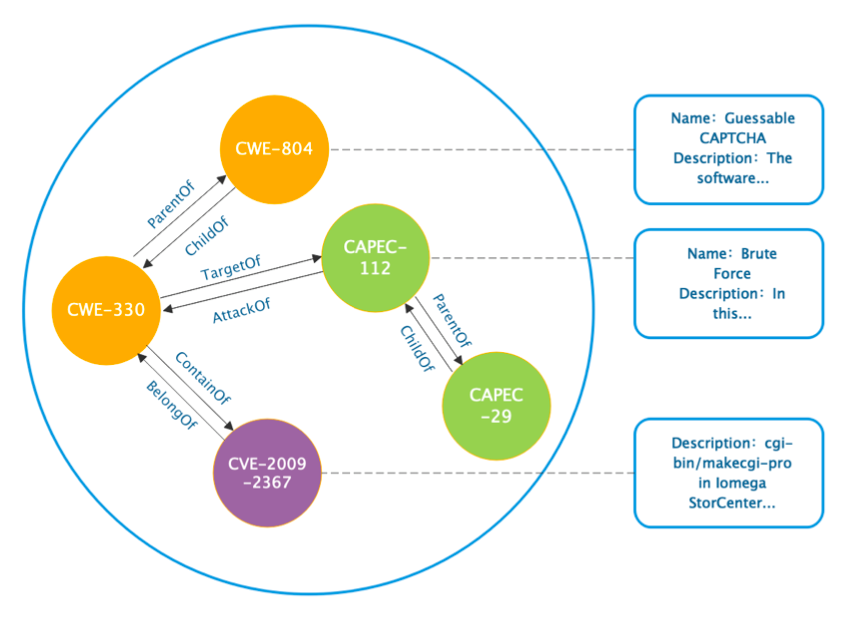
图2 知识图谱实例
本研究构建了基于CWE、CVE和CAPEC数据库的软件安全知识图谱。实验数据库收集自2021年11月5日的版本。提取CWE ID、CVE ID、CAPEC ID作为实体,CVE、CWE、CAPEC的标题和描述作为实体的纹理信息,提取不同实体之间的关系形成三元组。创建12种类型的关系,然后对数据集中的互补关系进行补充。实现这一步是为了通过多跳的操作,帮助实体尽可能多地查找到它们的邻居信息。
五、总 结在构建软件安全知识图谱中,提出了预测软件安全实体关系的模型,在未来,希望该方法能够在各个领域的网络安全问题中得到验证。利用软件安全知识边缘图模型在真实数据集上进行了测试,为应用于其他领域的知识图实体关系预测问题奠定了基础。这里的工作可能会激发必要性,并鼓励进一步研究预测软件安全和漏洞检测。
参考文献[1] K. Liu, F. Wang, Z. Ding, S. Liang, Z. Yu, and Y. Zhou, “A review of knowledge graph application scenarios in cyber security,” arXiv preprint arXiv:2204.04769, 2022.
[2] Z. Zhang, J. Cai, Y. Zhang, and J. Wang, “Learning hierarchy-aware knowledge graph embeddings for link prediction,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 03, 2020, pp. 3065–3072.
[3]Z. Han, X. Li, H. Liu, Z. Xing, and Z. Feng, “Deepweak: Reasoning
common software weaknesses via knowledge graph embedding,” in 2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 2018, pp. 456–466.
[4] H. Xiao, Z. Xing, X. Li, and H. Guo, “Embedding and predicting software security entity relationships: A knowledge graph based ap- proach,” in International Conference on Neural Information Processing. Springer, 2019, pp. 50–63.
[5] L. Yuan, Y. Bai, Z. Xing, S. Chen, X. Li, and Z. Deng, “Predicting entity relations across different security databases by using graph attention network,” in 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 2021, pp. 834–843.
[6]N.Rastogi,S.Dutta,R.Christian,M.Zaki,A.Gittens,andC.Aggarwal, “Information prediction using knowledge graphs for contextual malware threat intelligence,” arXiv preprint arXiv:2102.05571, 2021.
[7] W. Wang, H. Zhou, K. Li, Z. Tu, and F. Liu, “Cyber-attack behavior knowledge graph based on capec and cwe towards 6g,” in International Symposium on Mobile Internet Security. Springer, 2021, pp. 352–364.
[8]A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” Advances in neural information processing systems, vol. 26, 2013.
[9] Z.Wang,J.Zhang,J.Feng,andZ.Chen,“Knowledgegraphembedding by translating on hyperplanes,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 28, no. 1, 2014.
[10] Y.Lin,Z.Liu,M.Sun,Y.Liu,andX.Zhu,“Learningentityandrelation embeddings for knowledge graph completion,” in Twenty-ninth AAAI conference on artificial intelligence, 2015.
[11]R.Socher,D.Chen,C.D.Manning,andA.Ng,“Reasoningwithneural tensor networks for knowledge base completion,” Advances in neural information processing systems, vol. 26, 2013.
[12] N. Veira, B. Keng, K. Padmanabhan, and A. G. Veneris, “Unsupervised embedding enhancements of knowledge graphs using textual associa- tions.” in IJCAI, 2019, pp. 5218–5225.
[13] R. Xie, Z. Liu, J. Jia, H. Luan, and M. Sun, “Representation learning of knowledge graphs with entity descriptions,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 30, no. 1, 2016.
 通过查看网页源代码可以发现,网页设计师们最常用的是 Windows 平台中的“微软雅黑”、“宋体”等字体。与我在经验“Ubuntu 里为 LibreOffice 设置替换显示字体”中提到的相似的原因,在 Ubuntu 中浏览网页时,由于字体对不上,网页内容一般也都是显示为黑体字,比较单调。除了从 Windows 平台复制字体到 Ubuntu 平台这一方法之外,其实我们可以通过设定字体替换,让网页上常用的“黑体”、“宋体”由 Ubuntu 调用相应的字体显示,让网页外观在两个平台上有近似的显示效果。在 Ubuntu 平台上打开网页,满眼都是黑体字。难道网页设计师就是这样设计的吗?在网页空白处右键,在弹出菜单中点击“查看源代码”(或类似的选项),在其中找到网页 css 链接并打开,可以看到,网页设计师并不是只用“黑体”一种字体。如图,该网页的设计师使用了“黑体”、“宋体”两种字体显示中文。为了让 Ubuntu 平台上浏览网页时,能够看到与网页设计师原始设计接近的效果,我们需要替换字体。软件名称:Font Creator Program v4.1 绿色汉化破解版(字体制作编辑修改工具)软件大小:3MB更新时间:2013-05-131、首先,要安装一款叫做“Font Manager“的软件。Font Manager 安装完成后,点击启动它。待启动完成后,在窗口左侧下方,点击字体设置按钮(上面带有a、b两个字母的按钮)。2、在弹出的菜单中,点选“Alias Editor“。3、弹出 Alias Editor 窗口,点击右侧的 Add Alias (添加字体别名)按钮。4、左侧输入窗口中会出现一个默认字符为“Family”的条目,双击它,并改为“宋体”,然后回车;再点击窗口右侧的 “Add Substitute”(添加字体替换)按钮。5、在上一步骤输入“宋体”的条目下方,会出现默认字符为“Subtitute”的条目,同样双击,改为“AR PL UMing CN”(输入“AR”两个字母后,下方会弹出字体列表,可以从中选择)、回车。6、用同样的方法,输入以下字体及其替换:SimSun——AR PL UMing CN;黑体——Droid Sans Fallback;等等,如图。7、最后点击窗口右下角的“Write configure”(写入配置文件)按钮,窗口关闭,回到 Font Manager 主窗口,在弹出的 Font Manager needs to reload 对话框中,点击“Reload”。8、注销 Ubuntu 登录(注意保存正在编辑的文档)、重新登录。9、再打开第1步骤中打开过的网页,会看到网页字体区分内容,由不同的字体显示不同的内容了。标题由黑体负责显示,内容由宋体负责显示,错落有致,不会视觉疲劳。相关推荐: Ubuntu系统中LibreOffice怎么替换显示字体? ubuntu系统中删除/卸载自行安装的字体的方法
通过查看网页源代码可以发现,网页设计师们最常用的是 Windows 平台中的“微软雅黑”、“宋体”等字体。与我在经验“Ubuntu 里为 LibreOffice 设置替换显示字体”中提到的相似的原因,在 Ubuntu 中浏览网页时,由于字体对不上,网页内容一般也都是显示为黑体字,比较单调。除了从 Windows 平台复制字体到 Ubuntu 平台这一方法之外,其实我们可以通过设定字体替换,让网页上常用的“黑体”、“宋体”由 Ubuntu 调用相应的字体显示,让网页外观在两个平台上有近似的显示效果。在 Ubuntu 平台上打开网页,满眼都是黑体字。难道网页设计师就是这样设计的吗?在网页空白处右键,在弹出菜单中点击“查看源代码”(或类似的选项),在其中找到网页 css 链接并打开,可以看到,网页设计师并不是只用“黑体”一种字体。如图,该网页的设计师使用了“黑体”、“宋体”两种字体显示中文。为了让 Ubuntu 平台上浏览网页时,能够看到与网页设计师原始设计接近的效果,我们需要替换字体。软件名称:Font Creator Program v4.1 绿色汉化破解版(字体制作编辑修改工具)软件大小:3MB更新时间:2013-05-131、首先,要安装一款叫做“Font Manager“的软件。Font Manager 安装完成后,点击启动它。待启动完成后,在窗口左侧下方,点击字体设置按钮(上面带有a、b两个字母的按钮)。2、在弹出的菜单中,点选“Alias Editor“。3、弹出 Alias Editor 窗口,点击右侧的 Add Alias (添加字体别名)按钮。4、左侧输入窗口中会出现一个默认字符为“Family”的条目,双击它,并改为“宋体”,然后回车;再点击窗口右侧的 “Add Substitute”(添加字体替换)按钮。5、在上一步骤输入“宋体”的条目下方,会出现默认字符为“Subtitute”的条目,同样双击,改为“AR PL UMing CN”(输入“AR”两个字母后,下方会弹出字体列表,可以从中选择)、回车。6、用同样的方法,输入以下字体及其替换:SimSun——AR PL UMing CN;黑体——Droid Sans Fallback;等等,如图。7、最后点击窗口右下角的“Write configure”(写入配置文件)按钮,窗口关闭,回到 Font Manager 主窗口,在弹出的 Font Manager needs to reload 对话框中,点击“Reload”。8、注销 Ubuntu 登录(注意保存正在编辑的文档)、重新登录。9、再打开第1步骤中打开过的网页,会看到网页字体区分内容,由不同的字体显示不同的内容了。标题由黑体负责显示,内容由宋体负责显示,错落有致,不会视觉疲劳。相关推荐: Ubuntu系统中LibreOffice怎么替换显示字体? ubuntu系统中删除/卸载自行安装的字体的方法
鑫谷巡洋舰Q5(探索奢华与科技的完美融合)
- 最近更新
- 2025-11-05 11:15:18电脑系统更换教程(详细步骤和注意事项,让你轻松回归经典XP系统)
- 2025-11-05 11:15:18三大特征选择策略,有效提升你的机器学习水准
- 2025-11-05 11:15:18都100%代码覆盖了,还会有什么问题?
- 2025-11-05 11:15:18为什么我们的web前端变的越来越复杂
- 2025-11-05 11:15:18假如你最近安装或是更新到Ubuntu Gnome 14.04 LTS,你将能享受到一个稳定和可靠的Gnome shell体验。但Ubuntu 14.04中使用的是Gnome 3.10而并非最新的Gnome 3.12,那该如何升级到Gnome 3.12呢?升级前需要先了解为什么默认的是Gnome 3.10Gnome 3.12于3月下旬发布,虽然早于Ubuntu 14.04发布却并未集成在Ubuntu Gnome 14.04中。这是因为Gnome 3.12的开发周期使得其没有足够的时间进行审查和测试来支持LTS版本,默认的Gnome 3.10则能保证其稳定性。这就是不推荐升级至Gnome 3.12的原因。假如你已明了会遇到的风险还想升级至Gnome 3.12,你可以参看下面的方法。在升级之前请确保使用的是Ubuntu 14.04,同时安装了Gnome 3.10。假如你使用的是Unity等非Gnome桌面环境,还需要先安装Gnome 3.10。apt:gnome-shell(点击安装)然后确保系统已经更新,复制代码代码如下:复制代码代码如下:复制代码代码如下:sudo apt-get install ppa-purgesudo ppa-purge ppa:gnome3-team/gnome3-staging
- 2025-11-05 11:15:18靠默契保证的私有制:Python 中的私有
- 2025-11-05 11:15:18资深架构师解读Java多线程与并发模型之锁
- 2025-11-05 11:15:18手把手带你,用Python写一个Monkey自动化测试脚本!!!
- 热门排行
- 2025-11-05 11:15:18GoogleFiber(探索GoogleFiber的高速网络和创新技术)
- 2025-11-05 11:15:18NoSQL还是SQL?这一篇讲清楚
- 2025-11-05 11:15:18爬了知乎200万数据,图说程序员都喜欢去哪儿工作
- 2025-11-05 11:15:18PHP代码简洁之道——SOLID原则
- 2025-11-05 11:15:18用K701耳机听流行音乐的细腻之旅(透过K701耳机,感受流行音乐的细微之处)
- 2025-11-05 11:15:18没有对比就没有伤害,优秀的代码VS糟糕的代码
- 2025-11-05 11:15:18微服务后如何做一次系统梳理
- 2025-11-05 11:15:18泥瓦匠 5 年 Java 的成长感悟(下)