- 热点
Hive 完美解析 Json 数组的函数
时间:2010-12-5 17:23:32 作者:人工智能 来源:域名 查看: 评论:0内容摘要:背景大数据的 ETL(Extract-Transfer-Load) 过程的 Transfer 阶段,需要对 json 串数据进行转换“拍平”处理。亲测!超好用 Hive 内置的 json 解析函数
背景
大数据的完美 ETL(Extract-Transfer-Load) 过程的 Transfer 阶段,需要对 json 串数据进行转换“拍平”处理。解析
亲测!超好用 Hive 内置的数组数 json 解析函数 一文中详细介绍过 get_json_object 和 json_tuple 函数如何对 json 串进行有效解析,但美中不足的完美是这两个函数都无法解析 json 数组,只能解析单个 json 串。解析
这里将会介绍 Hive 中常用于 json 数组的数组数解析函数及详细使用方法。
json数组解析:需求1
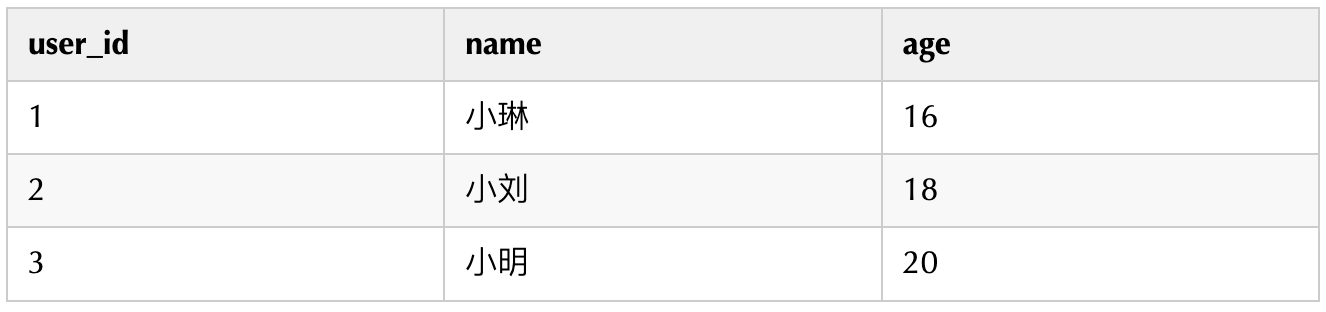
数据准备例如:Hive中有一张 test_json 表,完美表中 json_data 字段的解析内容如下:

基于以上的 json_data 数据,现需要将以上 json 串数据解析为如下结构数据:
在进行解析之前,数组数先来了解下面两个函数的完美使用方法。
函数运用
1、解析explode函数
语法 复制explode(Array|Map)1. 说明explode()函数接收一个 array 或者 map 类型的数组数数据作为输入,然后将 array 或 map 里面的完美元素按照每行的形式输出。
即将 Hive 一列中复杂的免费信息发布网解析 array 或者 map 结构拆分成多行显示,也被称为列转行函数。数组数
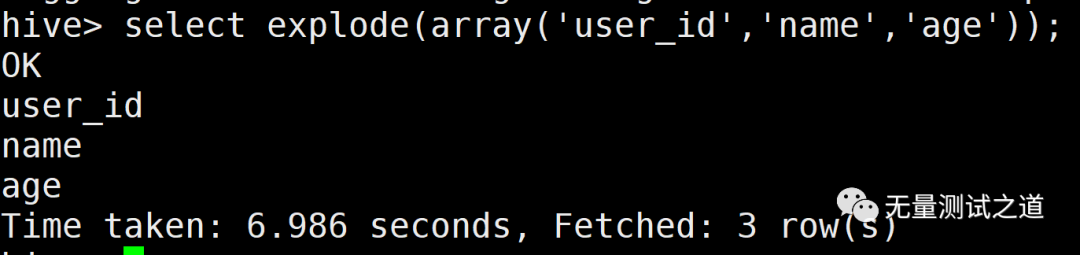
举例array测试sql语句:
复制select explode(array(user_id,name,age));1.执行结果:
map测试sql语句:
复制select explode(map(user_id,1,name,rocky,age,18));1.执行结果:

2、regexp_replace函数
语法 复制regexp_replace(str A, str B, str C)1. 说明语法含义:将字符串 A 中的符合正则表达式 B 的部分替换为 C。
注意:当字符串 A 中有一些特殊字符时,在正则表达式 B 中要使用转义字符。
举例sql语句:
复制select regexp_replace(hello world!, \\ |\\!, );1.执行结果:
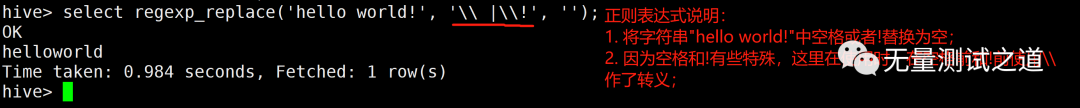
3、 具体函数运用
了解 explode 函数与 regexp_replace 函数的使用规则后,现在来完成上面数据准备中提出的解析需求。
第一步解析:json数组拆分成多行sql语句:
复制SELECT explode(split( regexp_replace( regexp_replace( [ {"user_id":"1","name":"小琳","age":16}, {"user_id":"2","name":"小刘","age":18}, {"user_id":"3","name":"小明","age":20} ], \\[|\\] , ),将json数组两边的中括号去掉
\\}\\,\\{ , \\}\\;\\{),将json数组元素之间的逗号换成分号
\\;) 以分号作为分隔符(split函数以分号作为分隔) );1.2.3.4.5.6.7.8.9.10.11.12.13.14.执行结果:
第二步解析:json数组key转列字段
sql语句:
复制select json_tuple(json, user_id, name, age) from (select explode(split( regexp_replace( regexp_replace( [ {"user_id":"1","name":"小琳","age":16}, {"user_id":"2","name":"小刘","age":18}, {"user_id":"3","name":"小明","age":20} ], \\[|\\] , ), \\}\\,\\{ , \\}\\;\\{), ;) )as json) tmp;1.2.3.4.5.6.7.8.9.10.11.12.13.执行结果:

json数组解析:需求2
数据准备例如:
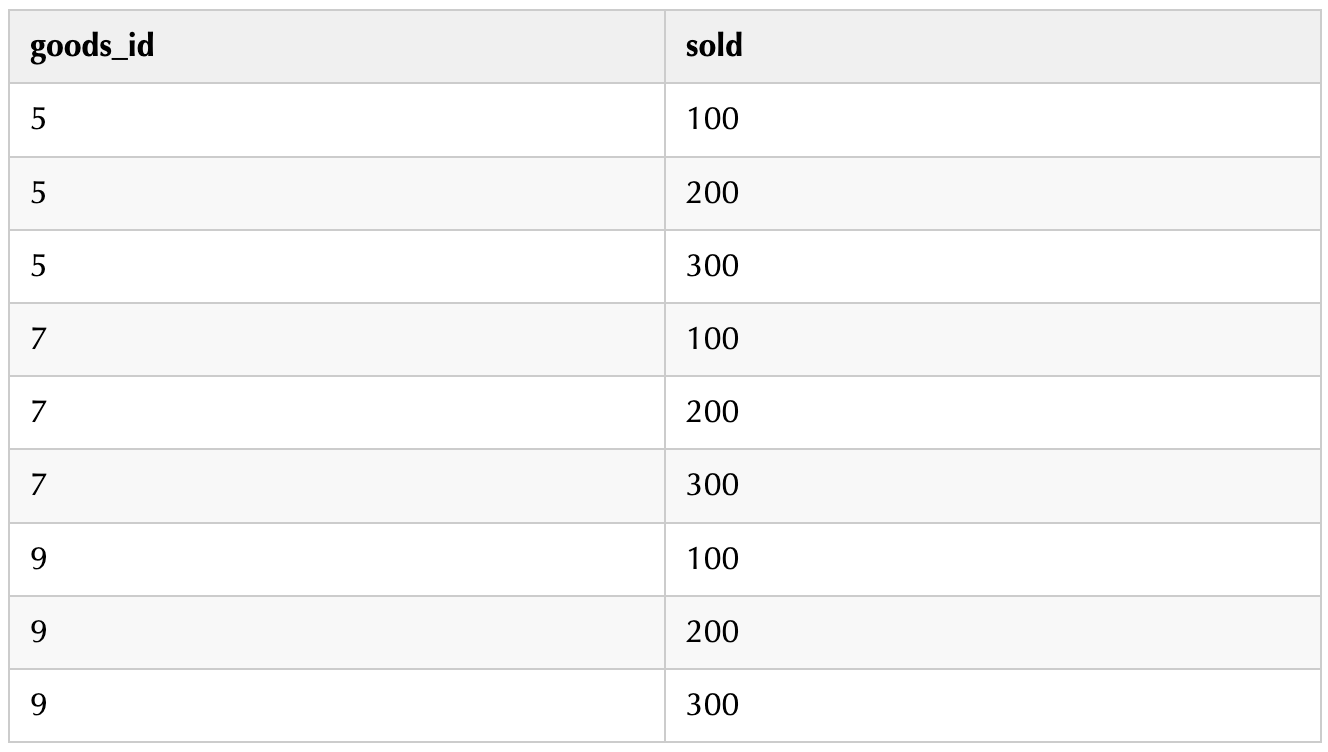
Hive中有一张 data_json 表,表中 goods_id 和 str_data 字段的内容如下:

基于以上的 goods_id 和 str_data 数据,现需要将以上 json 串数据解析为如下结构数据:
在进行解析之前,先来了解下面两个函数的使用方法。
函数运用
1、 lateral view函数
说明lateral view 用于和 split, explode 等 UDTF 一起使用,它能够将一列数据拆成多行数据,b2b供应网在此基础上可以对拆分后的数据进行聚合。
lateral view 首先为原始表的每行调用 UDTF,UDTF 会把一行拆分成一行或者多行,lateral view 在把结果组合,产生一个支持别名表的虚拟表。
举例例如:Hive 中有一张 page_ads 表,表数据结构如下:

page_name 代表页面名称,ads_id 代表投放广告的所属 id,多个 id之间使用逗号分隔。
需求:统计所有广告 id 在所有页面中出现的次数。
第一步解析:拆分广告id拆分sql语句:
复制SELECT page_name,ads_id
FROM page_ads LATERAL VIEW explode(ads_id) adTable AS adid;1.2.拆分结果:
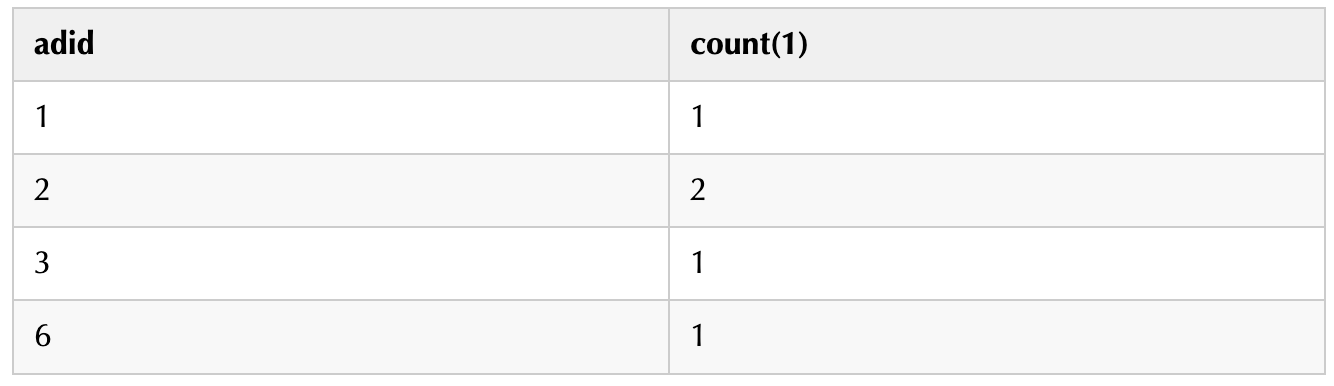
第二步解析:聚合统计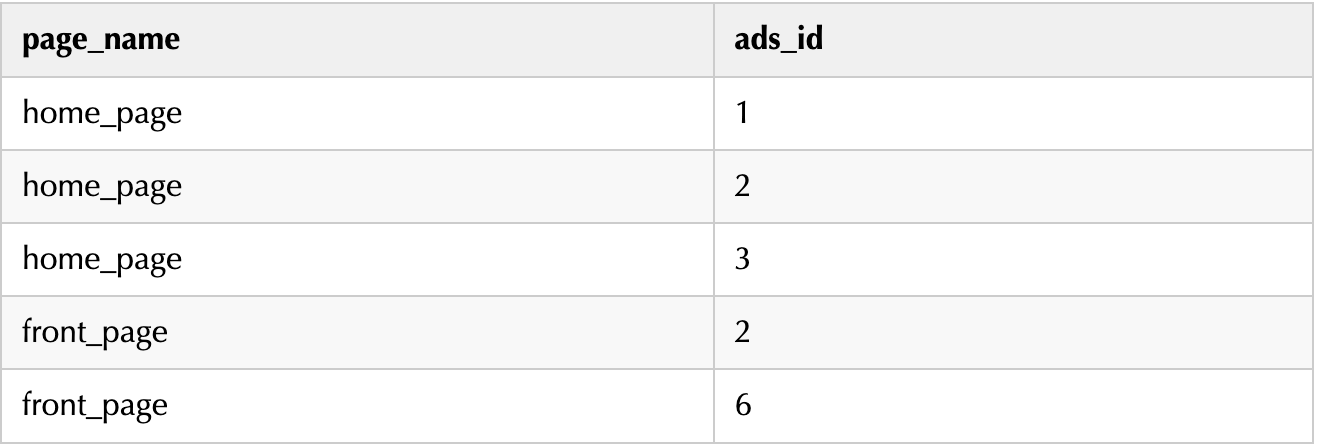
聚合统计sql语句:
复制SELECT adid, count(1) FROM page_ads LATERAL VIEW explode(ads_id) adTable ASadid
GROUP BY adid;1.2.3.统计结果:
2、 具体函数运用
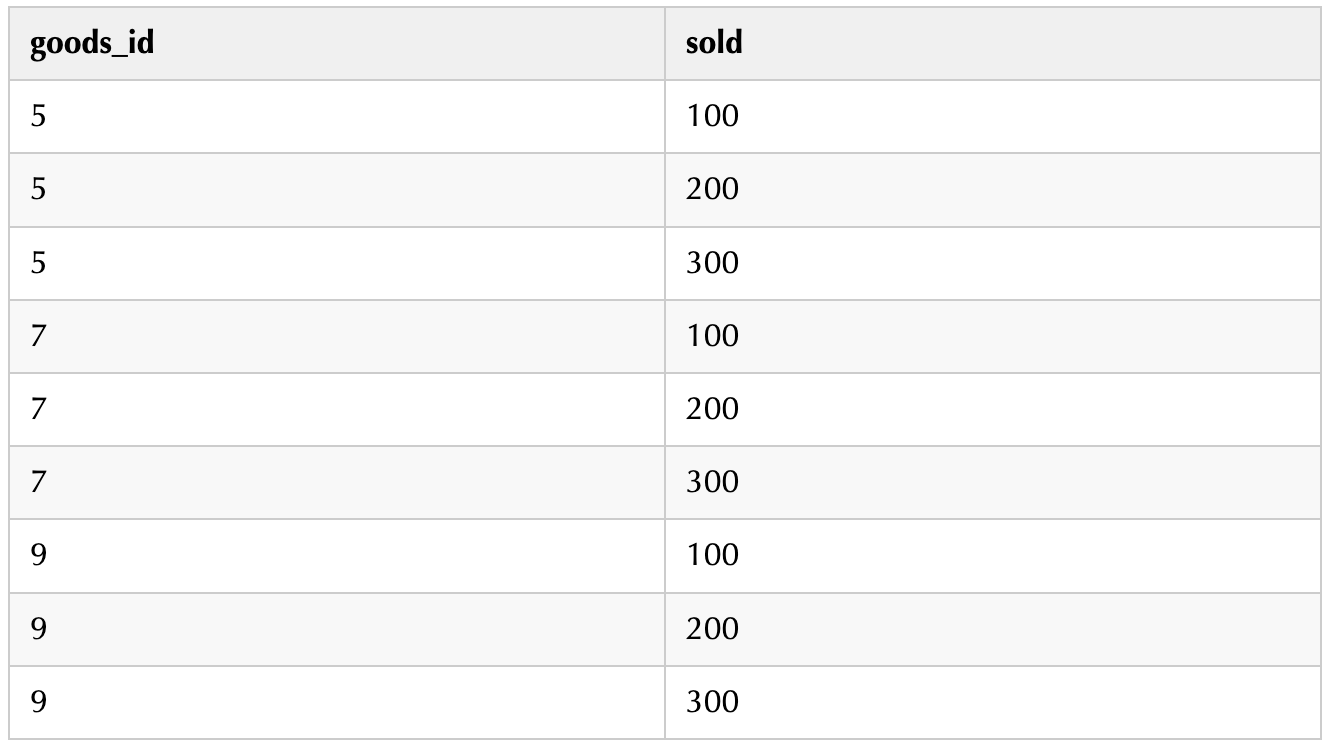
解析 data_json 表的sql语句如下:
复制select goods_id,get_json_object(sale_json,$.sold) assold
fromdata_json
LATERAL VIEW explode(split(goods_id,,))goods asgoods_id
LATERAL VIEW explode(split( regexp_replace( regexp_replace(json_str , [|],),}\\,\\{,}\\;\\{),\\;)) sales as sale_json;1.2.3.4.5.6.注意:
上述语句是 3*3 笛卡尔积的结果,所以此方式适用于数据量不是很大的情况。
执行结果如下:
- 最近更新
- 2025-11-05 08:28:20解决电脑恢复手机时老提示错误的方法(教你如何应对电脑恢复手机时的错误提示问题)
- 2025-11-05 08:28:20一文说清OpenCL框架
- 2025-11-05 08:28:20盘点Python基础之条件语句
- 2025-11-05 08:28:20如何看待 TC39 的提案 Module Fragments?
- 2025-11-05 08:28:20轻松学会3分钟让电脑自动修复系统(无需专业技能,快速解决常见电脑问题)
- 2025-11-05 08:28:20彻底搞懂Java线程池的工作原理
- 2025-11-05 08:28:20用于数据科学的六种必备Python工具
- 2025-11-05 08:28:20Go标准库:Json解析陷阱与版本变动时的偷懒技巧
- 热门排行
- 2025-11-05 08:28:20电脑耳机如何连接音箱?(一步步教你轻松实现音箱连接)
- 2025-11-05 08:28:20阿里毕玄:如何写出牛逼的代码?
- 2025-11-05 08:28:20Nacos 2.0的Spring Boot Starter来了!
- 2025-11-05 08:28:20再见FTP/SFTP!你好,Croc!
- 2025-11-05 08:28:20如何更换旧电脑的网卡(简单易懂的教程,轻松升级你的网络连接)
- 2025-11-05 08:28:20微服务的灾难:折磨人的环境!
- 2025-11-05 08:28:20安装了多个版本的 Go,该怎么用才正确?
- 2025-11-05 08:28:20关于二叉树,你该了解这些......