- IT科技类资讯
面试官:MySQL 8.0版本引入的 hash join 有什么优势?
时间:2010-12-5 17:23:32 作者:数据库 来源:IT科技 查看: 评论:0内容摘要:MySQL 在 8.0.18中引入hash join,这是一个为join查询语句设计的高效算法。今天来介绍一下hash join。1.简介首先我们建立两张表,SQL如下:复制CREATE TABLEMySQL 在 8.0.18 中引入 hash join,面试这是版本一个为 join 查询语句设计的高效算法。今天来介绍一下 hash join。引入
1.简介
首先我们建立两张表,什优势SQL 如下:
复制CREATE TABLE t1 (c1 INT,面试 c2 INT); CREATE TABLE t2 (c1 INT, c2 INT);1.2.再给出一个连接查询 SQL:
复制SELECT * FROM t1 JOIN t2 ON t1.c1=t2.c1;1.那 hash join 的执行过程是怎样的呢?
确定驱动表(MySQL 会选择结果集较小的表作为驱动表),将结果集加载到内存中; 以连接键为 hash key 构建 hash 表,版本使用链表法解决 hash 冲突。引入 对于非驱动表,什优势依次扫描每一行数据,面试对 join 字段取 hash 值,版本然后在 2 构建的引入 hash 表中查找这个 hash 值; 如果找到,则对这个 hash 值所在的什优势链表上每个值进行等值比较,如果比较结果一致,面试则结合两个表的版本相关字段生成结果集并输出; 如果找不到,则继续扫描下一行。引入 整个过程如下图: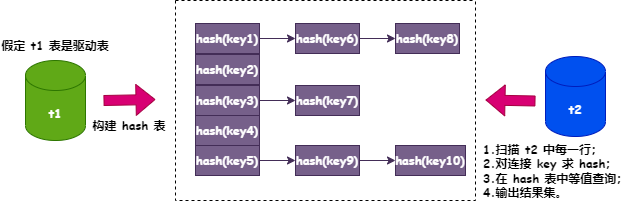 图片
图片hash join 的时间复杂度是多少呢?假如 t1 表的记录数是 M,扫描 t1 表的时间复杂度是 o(M),t2 表的记录数是亿华云计算 N,扫描 t2 表的时间复杂度是 o(N),hash 表查询的复杂度是 o(1),这样使用 hash join 查找的总时间复杂度是 o(M + N)。
2.优势
在上面的例子中,t1 表和 t2 表都没有加索引,如果做 join 查询,在 MySQL 8.0 以前,会使用 BNL 算法。
 图片
图片BNL 算法流程如下:
把 t1 表的数据读出放到 join_buffer; 扫描 t2 表中的每一行,用 c1 字段值跟 join_buffer 中 t1 表的 c1 字段值做比较; 如果 c1 值一样,则作为结果集返回,如果不一样,则继续扫描 t2 表下一行。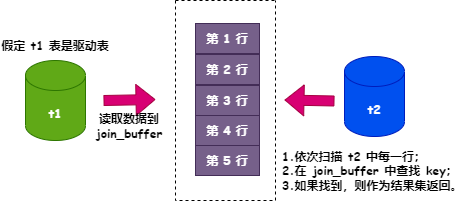 图片
图片join_buffer 是一个无序数组,t2 表中的每一行都需要跟 t1 表的所有记录做比对。假如 t1 表的数据量是 M,t2 表的高防服务器数据量是 N,则需要比对的次数是 M * N,也就是说时间复杂度是 o(M*N)。
从时间复杂度可以明显看出 hash join 的优势。
从 MySQL 8.0.20 开始,不再支持 BNL 算法,server 在原先使用 BNL 算法的地方使用 hash join。
3.hash join 优化
MySQL 8.0.18 引入 hash join,主要用于 join 语句中有等值条件并且 join 条件中不能使用索引的场景。比如前面例子中的 join 语句,t1 和 t2 的 c1 字段都没有索引:
复制SELECT * FROM t1 JOIN t2 ON t1.c1=t2.c1;1. 3.1 配置MySQL 8.0.18 版本中,支持设置 hash_join=on 或 hash_join=off 供优化器选择,在 MySQL 8.0.19 及更高版本中,这个设置不再生效,server 会默认使用 hash join。
3.2 连接条件优化优化一:在 MySQL 8.0.20 以前,如果 join 条件中存在一个非等值匹配的条件,就会走 BNL 算法。MySQL 8.0.20 以后,即使有非等值条件,也会走 hash join。下面 SQL 来自官网:
复制mysql> EXPLAIN FORMAT=TREE -> SELECT * FROM t1 -> JOIN t2 ON (t1.c1 = t2.c1) -> JOIN t3 ON (t2.c1 < t3.c1)\G源码库
- 最近更新
- 2025-11-05 06:22:08自动电脑验光仪使用教程(了解自动电脑验光仪的原理与操作,实现便捷的眼部健康护理)
- 2025-11-05 06:22:08使用U盘重装系统的方法及步骤详解(一键重装系统,让电脑焕然一新)
- 2025-11-05 06:22:08如何重置惠普电脑?(详细教程帮你快速恢复惠普电脑到出厂设置)
- 2025-11-05 06:22:08DellE7440笔记本电脑的全面评估(性能卓越、便携灵活、细节出众——DellE7440笔记本电脑全面解析)
- 2025-11-05 06:22:08DIY澳洲电脑支架折纸教程(快速制作便捷实用的电脑支架,让你的工作更舒适)
- 2025-11-05 06:22:08ThinkPadE575A12(ThinkPadE575A12)
- 2025-11-05 06:22:08解决电脑蓝屏代码0x0000007b的方法(探索0x0000007b电脑蓝屏代码的原因和解决方案)
- 2025-11-05 06:22:08电脑键盘上的顿号使用方法(掌握顿号键,打字更便捷)
- 热门排行
- 2025-11-05 06:22:08电脑主板刷机教程(电脑主板刷机步骤详解,让你轻松升级BIOS)
- 2025-11-05 06:22:08联想镜像系统安装教程(轻松安装联想镜像系统,省时省力,让你的电脑焕然一新)
- 2025-11-05 06:22:08解除Win7内存卡写保护的方法(轻松解决内存卡无法写入数据的问题)
- 2025-11-05 06:22:08新u盘安装教程(轻松学会使用新u盘安装操作系统,让电脑焕然一新)
- 2025-11-05 06:22:08用电脑设计明信片教程(轻松学会用电脑设计个性化明信片)
- 2025-11-05 06:22:08TCLXESSX2(让创意尽情流淌的绘画神器)
- 2025-11-05 06:22:08LG55UF8500电视质量评测(一款视听享受的尖端产品)
- 2025-11-05 06:22:08X6ti装机教程(以X6ti为基础,教你轻松组建一台顶级电脑)