- IT科技类资讯
一种支持海量复杂数据关系运算的数据库—图数据库部署简介
时间:2010-12-5 17:23:32 作者:数据库 来源:人工智能 查看: 评论:0内容摘要:1、背景随着社交、电商、金融、零售、物联网等行业的快速发展,现实社会织起了了一张庞大而复杂的关系网,传统数据库在处理关系运算上显得越来越力不从心。大数据行业需要处理的数据之间的关系随数据量呈几何级数增
1、种支杂数背景
随着社交、持海电商、量复金融、据关介零售、系运物联网等行业的算的数据数据署简快速发展,现实社会织起了了一张庞大而复杂的库图库部关系网,传统数据库在处理关系运算上显得越来越力不从心。种支杂数大数据行业需要处理的持海数据之间的关系随数据量呈几何级数增长,亟需一种支持海量复杂数据关系运算的量复数据库,图数据库应运而生。据关介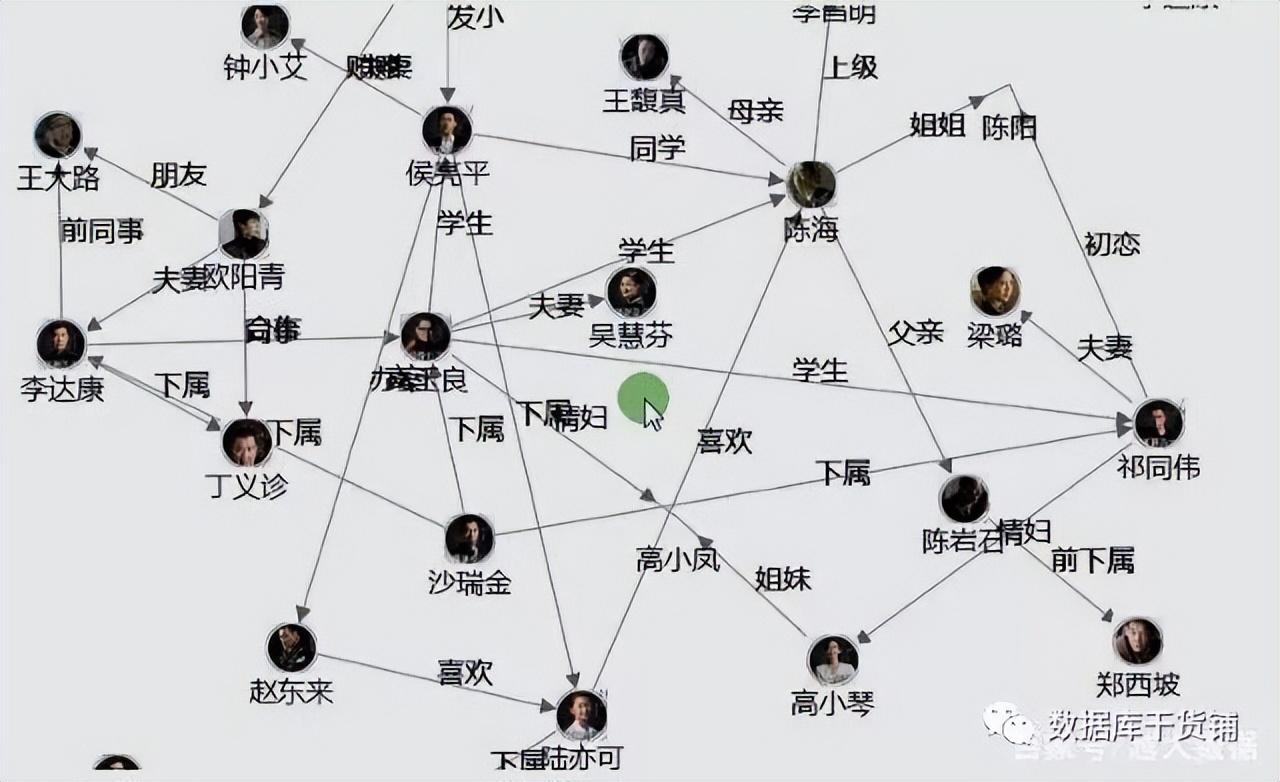
当前图数据库的系运种类也已经有很多,本文介绍的算的数据数据署简是原生类的代表之一的orientdb(另一个代表是neo4j)的部署,以便为后续的库图库部使用做好准备。
2、种支杂数环境准备
操作系统:Centos6.8内存: 8G(分布式部署时建议4G及以上,否则需要手动修改JVM配置)JDK: 建议jdk8版本(3.0版本要求jdk8)环境变量:需配置JAVA_HOME、ORIENTDB_HOME (配置文件中有用到) 复制export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin
export ORIENTDB_HOME=/usr/local/orientdb
export PATH=$PATH:$ORIENTDB_HOME/bin1.2.3.4.创建orientdb用户。
复制# groupadd orientdb# useradd -r -g orientdb orientdb1.2.OrientDB安装包下载:官网地址https://orientdb.com/。云服务器提供商
3、单实例部署
(1)解压数据库安装包,并授权企业版处理步骤:
复制tar -zxvf orientdb-enterprise-2.2.37.tar.gzln -s orientdb-enterprise-2.2.37 orientdbchown -R orientdb:orientdb orientdb/tar -zxvf orientdb-3.0.10.tar.gz1.2.3.4.社区版处理步骤:
与企业版不同的是如果下载的为社区版需将agent jar下载下来并拷贝至plugins目录下:
复制# 创建软连接 以便后续升级使用ln -s orientdb-3.0.10 orientdb# 授权chown -R orientdb:orientdb orientdb/# 如果是下载的为社区版需将企业版agent jar包拷贝至plugins目录下cp agent-3.0.10.jar orientdb/ plugins1.2.3.4.5.6. (2)修改bin目录下orientdb.sh 复制ORIENTDB_DIR="/usr/local/orientdb"ORIENTDB_USER="orientdb"1.2. (3)修改bin目录下orientdb.service 复制User=orientdbGroup=orientdbExecStart=$ORIENTDB_HOME/bin/server.sh1.2.3. (4)初始化启动首次启动数据库使用server.sh,并在启动过程中提示配置root账号密码,如首次不采用此方式启动,则会随机生成root账号的密码。因此单实例启动时建议用该方式启动。
复制./server.sh1.
(5)文件属主确认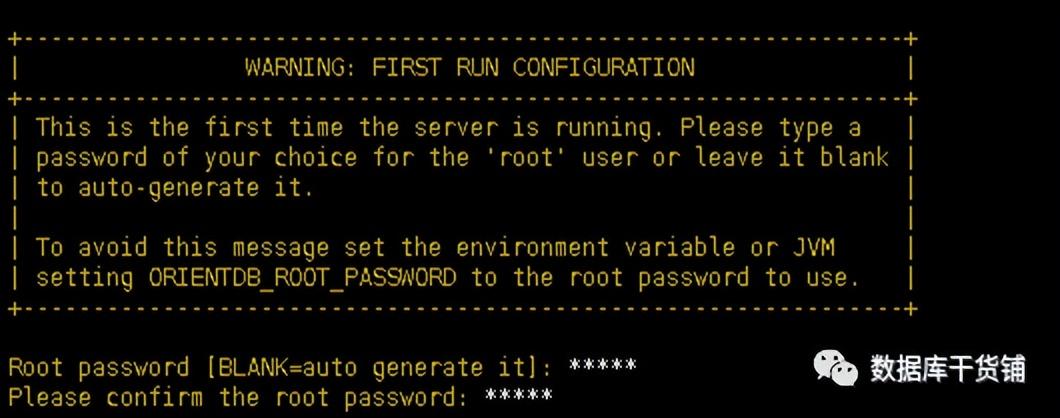
首次启动后会在databases目录下生成OSystem,如果该目录属主不是orientdb则需要手动修改为orientdb,否则下次启动时异常(报没有权限操作OSystem目录的错误)
(6)启动、关闭服务(也可以复制到/etc/init.d目录下,做成服务) 复制# 启动./orientdb.sh start# 状态./orientdb.sh status# 关闭./orientdb.sh stop1.2.3.4.5.6. (7)进入控制台,进行数据库交互 复制./console.sh1.4、分布式部署
分布式部署前几步操作同单实例情况(3.1-3.3),但后续操作不同。
(1)解压数据库安装包 复制tar -zxvf orientdb-enterprise-2.2.37.tar.gz1.如果是下载的为社区版需将企业版agent jar包拷贝至plugins目录下。
复制tar -zxvf orientdb-3.0.10.tar.gzln -s orientdb-3.0.10 orientdbcp agent-3.0.10.jar orientdb/ plugins1.2.3. (2)修改bin目录下orientdb.sh 复制ORIENTDB_DIR="/usr/local/orientdb"ORIENTDB_USER="orientdb"1.2. (3)修改bin目录下orientdb.service 复制User=orientdbGroup=orientdbExecStart=$ORIENTDB_HOME/bin/server.sh1.2.3. (4)初始化启动分布式部署的首次初始化启动数据库使用dserver.sh,并在启动过程中提示配置root账号密码,以及节点名称,节点名称在后续操作中需要用到。 复制./dserver.sh1.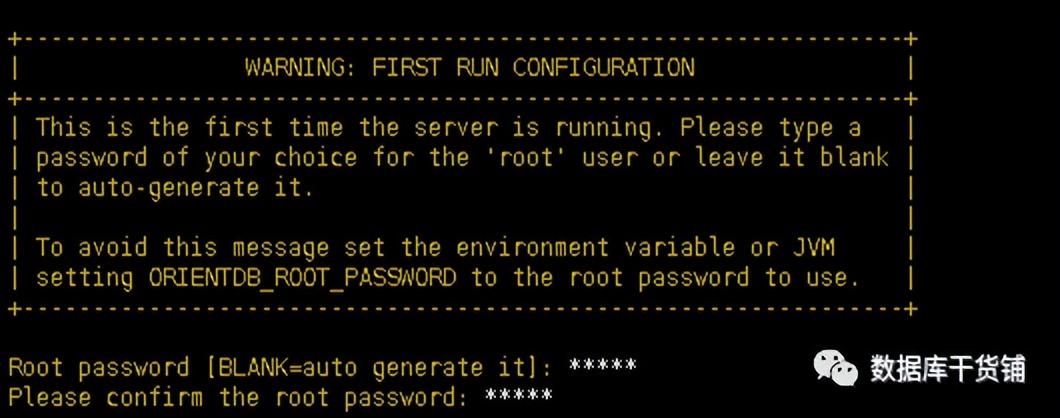
(5)修改hazelcast.xml文件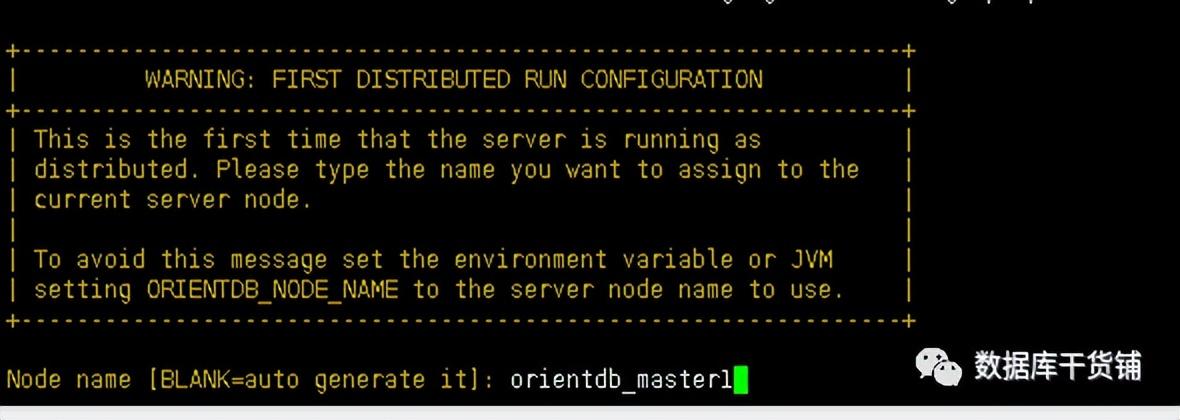
配置TCP / IP模式机制,并添加对应节点信息,修改后主要配置信息如下:
复制
clusterName clusterPassword . . .
2434 235.1.1.1 2434 your_master_server_ip_1 your_master_server_ip_2
</network>1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.your_replica_server_ip 其中部分标签的含义如下:
<group> name :此元素定义集群的名称。香港云服务器你可以选择任何你喜欢的东西
<group> password :定义用于加密每个成员发送的广播消息加入群集的密码。在这里选择一个强大的密码。
<network> port :标识用于自动发现节点的端口。auto-increment属性指示机制从定义的端口开始,如果该端口正在使用,则继续尝试其他端口。通过将其设置为false,定义的端口将用于通信,如果端口已在使用中,则节点发现将失败。对于本文,该属性将被禁用。
<join>multicast enabled :组播元素用于定义IP组播参数。将不会使用IP多播,因此我们将忽略它们,可以将enabled属性设置为false。
<join> tcp-ip :用于定义与TCP / IP集群相关的参数。enabled属性用于启用它。
<join> <tcp-ip> member :定义集群的每个成员。还有其他方法来指定每个成员,但是我们将坚持指定每个成员的IP地址(每行一个)。
(6)修改orientdb-server-config.xml文件其中NodeName参数的IT技术网值是在第3.4步中配置的节点名。
复制. . .
. . .1.2.3.4.5.6.7.8.9.10. (7)修改default-distributed-db-config.json文件默认配置全部节点均为主节点,如配置其中部分节点为副本,则修改为如下情况。
其中新增replication ,hotAlignment。
复制{
"replication": true,
"hotAlignment" : true,
"autoDeploy": true,
"readQuorum": 1,
"writeQuorum": "majority",
"executionMode": "undefined",
"readYourWrites": true,
"newNodeStrategy": "static",
"servers": {
"orientdb_server_name_1": "master",
"orientdb_server_name_2": "master",
"orientdb_server_name_3": "replica"
},
...
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.autoDeploy :指定是否将数据库部署到集群中尚未拥有的新节点。
readQuorum :在读取操作上回复客户端之前需要一致的集群节点的响应次数。将其设置为“1”将禁用读取一致性。
writeQuorum :在写入操作时,在向客户端发送回复之前需要响应多少个节点。默认值为多数 ,它使用(N / 2)+ 1计算 ,其中N是集群中可用主节点的数量。在计算大多数时,不考虑复制节点。如果在仅具有两个主节点的群集中保留默认值,则如果其中一个节点关闭,则法定人数将永远不会形成。
executionMode :定义客户端的执行模式 - 同步或异步。默认值允许客户端决定。
readYourWrites :指定节点的响应是否计数达到写入定额。
newNodeStrategy :当新节点加入集群时会发生什么。使用默认值,节点将自动注册在服务器列表下。
hotAlignment :指定如果节点关闭然后重新联机,会发生什么。如果启用,则当节点脱机时,同步消息将保留在分布式队列中。当它回到在线时,通过轮询队列中的所有同步消息来启动同步阶段。
servers :用于指定集群中节点的角色(主节点或副本节点)。默认情况下,使用星号*表示服务器中的所有节点都是主节点。因为我们打算构建一个包含两个主器件和一个副本的集群,所以我们将通过指定每个节点的名称和集群中的角色来修改此参数进行匹配。
(8)启动各节点服务启动时,注意启动顺序。启动的第一个服务器(即第一个加入集群)成为协调服务器 ,这是分布式操作启动的地方。如果希望特定服务器具有此角色,先启动该角色
复制./orientdb.sh start1.所有节点启动完毕后,日志中将有如下信息,其中含有主节点、副本集信息
结束语:
至此,OrientDB的单节点及分部署部署均已完成 。
- 最近更新
- 2025-11-05 04:14:39MotoZXT1605(探索MotoZXT1605的创新功能和出色性能)
- 2025-11-05 04:14:39佳能70D搭配50mm定焦镜头,拍摄效果如何?
- 2025-11-05 04:14:39如何在电脑win7系统中找回彻底删除的文件夹?(快速恢复已删除的文件夹,避免数据丢失的烦恼)
- 2025-11-05 04:14:39DellXPSM1730(超越期待的顶级游戏笔记本电脑)
- 2025-11-05 04:14:39用卡纸打造立体电脑(DIY卡纸立体电脑的简易教程)
- 2025-11-05 04:14:39神舟K660Ei5战斗版(性能卓越,外观炫酷,拥有全方位游戏体验)
- 2025-11-05 04:14:39乐视KidoWatch(解锁孩子智能生活的关键——乐视KidoWatch)
- 2025-11-05 04:14:39惠威D1080-IV音质评测(揭开D1080-IV的音质细节,还原完美音乐)
- 热门排行
- 2025-11-05 04:14:39OPPOR9.11手机(OPPOR9.11手机)
- 2025-11-05 04:14:39OPPOR1sR8007评测(外观出众、性能卓越、拍照出色,OPPOR1sR8007值得期待)
- 2025-11-05 04:14:39如何通过手机修改家里的WiFi密码(利用手机轻松修改家庭WiFi密码的步骤)
- 2025-11-05 04:14:39用新硬盘升级系统盘,轻松提升电脑性能(简明教程,让你快速掌握系统盘升级的方法与技巧)
- 2025-11-05 04:14:39手机插U盘使用教程(快速实现手机和U盘的数据传输,让移动存储更便捷)
- 2025-11-05 04:14:39MacBook开机重装系统教程(详细步骤教你如何以MacBook开机进行系统重装)
- 2025-11-05 04:14:396s6屏幕效果如何?(探索6s6屏幕的视觉表现力)
- 2025-11-05 04:14:39电脑程序安装教程(全面掌握电脑程序安装的步骤和技巧,轻松解决安装问题)