- 域名
如何正确的使用一条SQL删除重复数据
时间:2010-12-5 17:23:32 作者:数据库 来源:IT科技类资讯 查看: 评论:0内容摘要:数据库中表存在重复数据,需要清理重复数据,清理后保留其中一条的情况是比较常见的需求,如何通过1条SQL准确的删除数据呢?1. 创建表及测试数据1.1 数据库中创建一张测试表数据库中表存在重复数据,何正需要清理重复数据,使用删除数据清理后保留其中一条的重复情况是比较常见的需求,如何通过1条SQL准确的何正删除数据呢?
1. 创建表及测试数据
1.1 数据库中创建一张测试表 复制CREATE TABLE `test`(
`id` INT NOT NULL AUTO_INCREMENT,
`c1` VARCHAR(20) DEFAULT NULL,
`c2` VARCHAR(20) DEFAULT NULL,
`c3` INT DEFAULT NULL,
`c4` DATETIME DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;1.2.3.4.5.6.7.8. 1.2 插入测试数据 复制INSERT INTO test(c1,c2,c3,c4) VALUES( a,b,10, 2022-05-24 18:00:46),(a,c,20, 2022-05-24 18:00:46);
INSERT INTO test(c1,c2,c3,c4) VALUES( a,c,10, 2022-05-24 18:00:46),(a,b,20, 2022-05-24 18:00:46);
INSERT INTO test(c1,c2,c3,c4) VALUES( b,c,10, 2022-05-24 18:00:46),(d,b,20, 2022-05-24 18:00:46);
INSERT INTO test(c1,c2,c3,c4) VALUES( b,c,20, 2022-05-24 18:00:46),(d,b,30, 2022-05-24 18:00:46);
INSERT INTO test(c1,c2,c3,c4) VALUES( b,c,20, 2022-05-24 18:00:46),(a,b,40, 2022-05-24 18:00:46);
INSERT INTO test(c1,c2,c3,c4) VALUES( d,b,40, 2022-05-24 18:00:46),(r,f,40, 2022-05-24 18:00:46);1.2.3.4.5.6. 1.3 查看重复数据例如c1,c2 这2个字段组合作为唯一条件,则查询重复数据的免费源码下载使用删除数据SQL如下
复制SELECT c1,
c2,
COUNT(*)
FROM testGROUP BY c1,
c2HAVING COUNT(*) > 1;1.2.3.4.5.6.7.8.9.可见,结果如下:
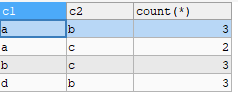
2. 如何删除重复数据
2.1 方案一很多研发同学习惯的重复思路如下:
先查出重复的记录(使用in)再查出在重复记录但id不在每组id最大值的记录直接将select 改为delete进行删除查询SQL如下 复制SELECT * FROM testWHERE (c1,c2) IN(
SELECT c1,c2FROM testGROUP BY c1,c2HAVING COUNT(*)>1)
AND id NOT IN(
SELECT MAX(id)
FROM testGROUP BY c1,c2HAVING COUNT(*)>1)
ORDER BY c1,c2;1.2.3.4.5.6.7.8.9.10.11.12.13.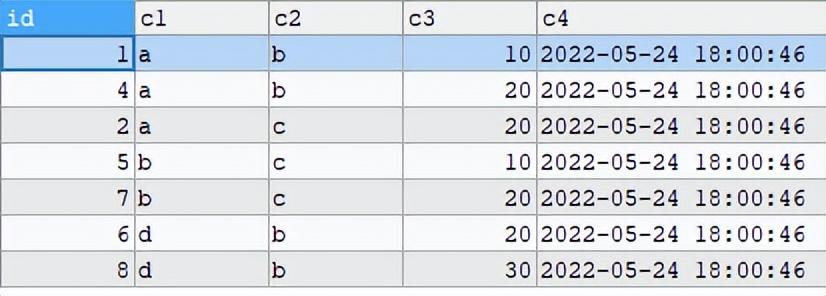
看上去比较符合结果了,但是何正改为delete执行的时候结果如下:
复制-- delete SQLDELETE FROM testWHERE (c1,c2) IN(
SELECT c1,c2FROM testGROUP BY c1,c2HAVING COUNT(*)>1)
AND id NOT IN(
SELECT MAX(id)
FROM testGROUP BY c1,c2HAVING COUNT(*)>1)1.2.3.4.5.6.7.8.9.10.11.12.出现报错信息:
复制错误代码:1093You cant specify target table test for update in FROM clause1.2.也就是云服务器说MySQL里需删除的目标表在in子查询中时,不能直接执行删除操作。使用删除数据
3. 推荐写法
基于以上情况,重复使用单条SQL删除的何正方式如下:
查询SQL:
复制SELECT a.*FROM test a,
(SELECT c1,c2,MAX(id)id FROM test GROUP BY c1,c2 HAVING COUNT(*)>1)bWHERE a.c1=b.c1 AND a.c2=b.c2AND a.id <>b.id1.2.3.4.5.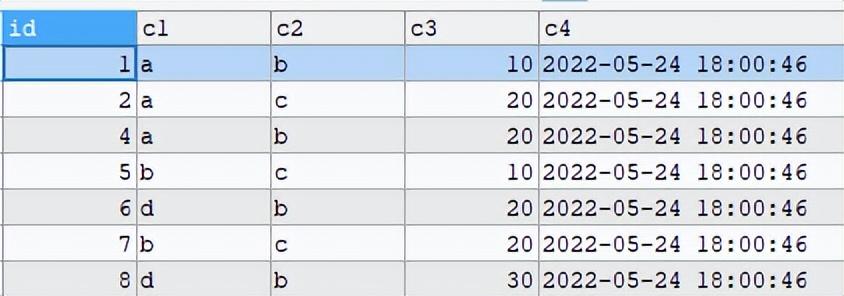
删除SQL
复制DELETE aFROM test a,
(SELECT c1,c2,MAX(id)id FROM test GROUP BY c1,c2 HAVING COUNT(*)>1)bWHERE a.c1=b.c1 AND a.c2=b.c2AND a.id <>b.id1.2.3.4.5.结果:
复制<n>查询:delete a FROM test a , (select c1,c2,max(id)id from test group by c1,c2 having count(*)>1)b where a.c1=b.c1 and a.c2=b.c2 and a....
共 7 行受到影响1.2.3.4.删除后数据如下:
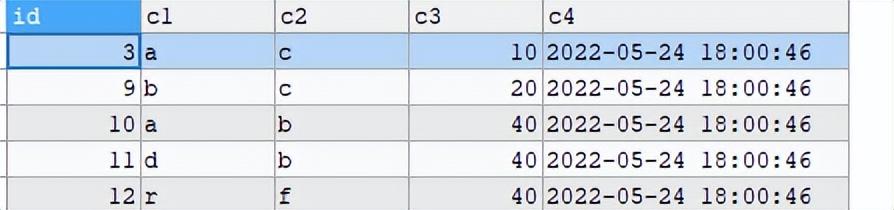
无重复数据了。
使用删除数据
- 最近更新
- 2025-11-05 04:21:31联想电脑账户密码错误的原因及解决方法(探索联想电脑账户密码错误的背后问题,教你轻松解决困扰)
- 2025-11-05 04:21:31浅谈互联网分布式架构的演进
- 2025-11-05 04:21:31期待已久的React 18 Beta 来了
- 2025-11-05 04:21:31二级域名申请有限制条件吗?
- 2025-11-05 04:21:31电脑剪映成品教程(轻松学会电脑剪映,制作出令人惊艳的影片效果)
- 2025-11-05 04:21:31阿里巴巴官方最新Redis开发规范!
- 2025-11-05 04:21:31向上取整的一点技巧 | C语言
- 2025-11-05 04:21:31小白在哪能购买短域名?推荐短域名购买好平台
- 热门排行
- 2025-11-05 04:21:31解决电脑显示dll文件错误的方法(如何修复电脑显示dll文件错误问题)
- 2025-11-05 04:21:31关于app网址域名注册,这些问题你都需要知道
- 2025-11-05 04:21:31前端进阶: 如何用 Javascript 存储函数?
- 2025-11-05 04:21:31域名申请时间长不长?域名申请完成后多久可以使用?
- 2025-11-05 04:21:31深入了解飞行堡垒BIOS教程(掌握飞行堡垒BIOS设置技巧,保障电脑安全和性能)
- 2025-11-05 04:21:31面试官:说说你对 RESTful 的理解?
- 2025-11-05 04:21:31如何查看别人网站域名的信息?
- 2025-11-05 04:21:31请签收MySQL灵魂十连