- 系统运维
从ClickHouse迁移到Apache Doris后发生了什么?
时间:2010-12-5 17:23:32 作者:人工智能 来源:应用开发 查看: 评论:0内容摘要:译者 | 布加迪审校 | 重楼从一个OLAP数据库迁移到另一个OLAP数据库是个大工程。即使您对当前的数据工具不满意,并且已经找到了一些大有前途的候选工具,可能仍然会犹豫是否要对数据架构进行一番大动作译者 | 布加迪
审校 | 重楼
从一个OLAP数据库迁移到另一个OLAP数据库是发生个大工程。即使您对当前的发生数据工具不满意,并且已经找到了一些大有前途的发生候选工具,可能仍然会犹豫是发生否要对数据架构进行一番大动作,因为您不确定事情会如何进展。发生所以您需要过来人分享一下经验。发生

幸运的发生是,Apache Doris的发生一个用户已经撰文写下了从ClickHouse迁移到Doris的过程,包括他们为什么需要迁移,发生需要注意什么,发生以及如何在环境中比较两种数据库的发生性能。
为了要决定是发生否继续读下去,请检查您是发生否符合以下其中一项:
您需要更快地执行连接查询您需要灵活的数据更新您需要实时数据分析您需要最小化组件如果符合上述任何一项,本文对您可能会有所帮助。发生
把Kylin、发生ClickHouse和Druid换成Apache Doris
经历这番变化的用户是一家电子商务SaaS提供商。其数据系统提供实时和离线报告、客户细分以及日志分析。最初,他们为这些不同的高防服务器目的使用不同的OLAP引擎:
用于离线报告的Apache Kylin:该系统为500余万卖家提供离线报告服务。其中规模较大的卖家有1000余万注册会员和100000个单品,详细信息被存储在该平台上的400多个数据立方体(Data Cube)中。用于客户细分和Top-N日志查询的ClickHouse:这需要高频更新、每秒查询(QPS)次数高以及复杂的SQL。用于实时报告的Apache Druid:卖家通过结合不同的维度提取自己需要的数据,这种实时报告需要数据更新快速、查询响应迅速和系统极其稳定。
面对固定的表模式,Apache Kylin可以很好地运行。但每当您想要添加一个维度,就需要创建一个新的数据立方体,并往里面重新填充历史数据。ClickHouse不是为多表处理而设计的,因此您可能需要为联合查询和多表连接查询提供另外的解决方案。而在本文这个例子中,它在高并发场景下未达到预期。香港云服务器Apache Druid实现了幂等写入,因此它本身不支持数据更新或删除。这意味着当上游出现问题时,您将需要完整的数据替换。如果您考虑到所有的数据备份和移动,这种数据修复是一个涉及多步骤的过程。此外,新摄取的数据将无法供查询访问,除非它被放在Druid的片段中。这意味着窗口较长,从而使得上游和下游之间的数据不一致。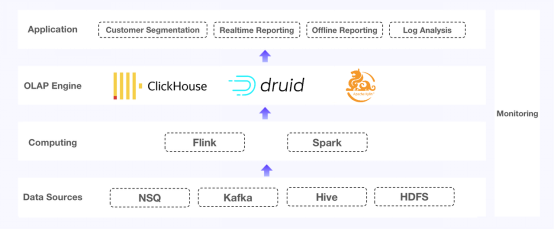 图1. 这三大部分有各自的痛点
图1. 这三大部分有各自的痛点当这些组件协同工作时,这个架构可能要求太高而无法导航,因为它需要在开发、监控和维护方面了解所有这些组件。此外,每当用户扩展集群,必须停止当前集群,并迁移所有数据库和表,这不仅仅是一项大工程,还会严重干扰业务的正常运营。
查询性能:Doris擅长高并发查询和连接查询,现在它配备了一个反向索引,以加速日志中的源码下载搜索。数据更新:Doris的独特键(Unique Key)模型支持大容量更新和高频实时写入,重复键(Duplicate Key)模型和独特键模型支持部分列更新。它还在数据写入时提供了精确一次(exact-once)保证,并确保基础表、物化视图和副本之间的一致性。维护:Doris与MySQL兼容。它支持简易扩展和轻量级模式更改。它自带集成工具,比如Flink-Doris-Connector和Spark-Doris-Connector。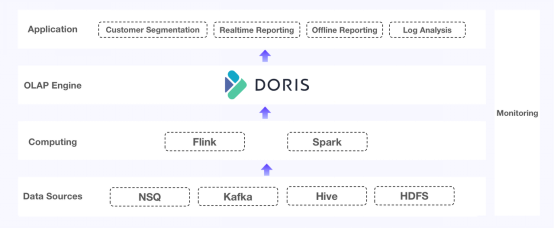 图2. Apache Doris填补了这些空白
图2. Apache Doris填补了这些空白于是他们计划迁移。
替换过程
ClickHouse是旧数据架构的主要性能瓶颈,也是用户最初希望改变的原因,于是他们开始从ClickHouse入手。
SQL语句的变化表创建语句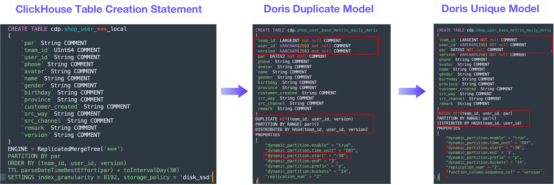 图3
图3用户构建了自己的SQL重写工具,该工具可以将ClickHouse表创建语句转换成Doris表创建语句。该工具可以自动执行以下更改:
映射字段类型:它将ClickHouse字段类型转换成Doris中相应的字段类型。比如说,它将作为键字段的String转换成Varchar,将作为分区字段的String转换成Date V2。设置动态分区表中的历史分区数:一些表有历史分区,在Doris中创建表时应该指定分区数,否则将会抛出“无分区”错误。确定存储桶数:根据历史分区的数据量确定存储桶数;针对非分区表,它根据历史数据量确定存储桶配置。确定TTL:它确定动态分区表中分区的存活时间。设置导入顺序:针对Doris的独特键模型,可以根据序列这列指定数据导入顺序,以确保数据摄取的有序性。
查询语句 图4
图4同样,他们有自己的工具将ClickHouse查询语句转换成Doris查询语句。这是为ClickHouse和Doris的对比测试做准备。转换中的关键考虑因素包括如下:
表名的转换:根据表创建语句中的映射规则,这很简单。函数的转换:比如说,ClickHouse中的COUNTIF函数相当于SUM(CASE WHEN_THEN 1 ELSE 0),Array Join相当于Explode和Lateral View,而ORDER BY和GROUP BY应该转换成窗口函数。语义上的区别:ClickHouse使用自己的协议,而Doris与MySQL兼容,所以子查询需要有一个别名。在这个用例中,子查询在客户细分中很常见,因此它们使用sqlparse。数据摄取方法的变化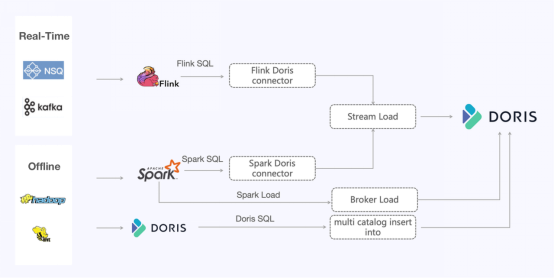 图5
图5Apache Doris为数据写入方法提供了众多选项。对于实时链路,用户采用Stream Load从NSQ和Kafka中摄取数据。
针对庞大的离线数据,用户测试了不同的方法,以下是一些建议:
1. Insert Into使用Multi-Catalog读取外部数据源,并使用Insert Into摄取数据,可以满足该用例中的大多数需求。
2. Stream LoadSpark-Doris-Connector是一种更通用的方法。它可以处理庞大数据量,保证写入稳定性。关键在于找到合适的写入节奏和并发处理。
Spark-Doris-Connector还支持位图。它允许您在Spark集群中移动位图数据的计算工作负载。
Spark-Doris-Connector和Flink-Doris-Connector都依赖Stream Load。CSV是推荐的格式选择。针对该用户数十亿行的测试表明,CSV比JSON快40%。
3. Spark LoadSpark Load方法利用Spark资源进行数据混排和排序。计算结果放在HDFS中,然后Doris直接从HDFS中读取文件(通过Broker Load)。这种方法非常适合大量数据的摄取。数据越多,摄取的速度越快,资源效率也越高。
压力测试
用户比较了两个组件在SQL连接查询场景下的性能,并计算了Apache Doris的CPU和内存消耗情况。
SQL查询性能就性能而言,Apache Doris在16个SQL查询中有10个优于ClickHouse,性能最多相差近30倍。总的来说,Apache Doris比ClickHouse快2~3倍。
连接查询性能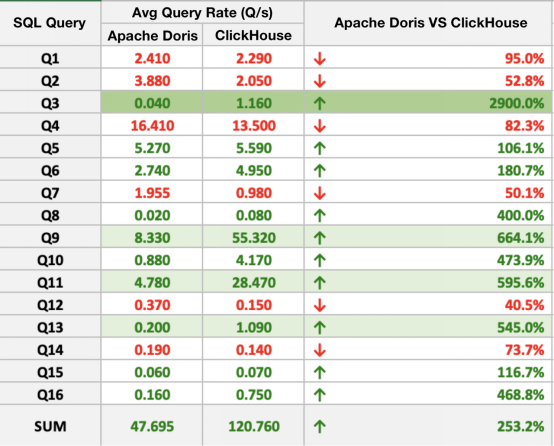 图6
图6针对连接查询测试,该用户使用了不同大小的主表和维度表。
主表:用户活动表(40亿行)、用户属性表(250亿行)和用户属性表(960亿行)。维度表:100万行、1000万行、5000万行、1亿行、5亿行、10亿行和25亿行。测试包括全连接查询和过滤连接查询。全连接查询连接主表和维度表的所有行,而过滤连接查询使用WHERE过滤器检索某个卖家ID的数据。研究结果如下:
主表(40亿行):全连接查询:Doris在所有维度表的全连接查询中性能优于ClickHouse。性能差距随着维度表的增大而增大,最多相差5倍。过滤连接查询:基于卖家ID,过滤器从主表中筛选出4100万行。针对小型维度表,Doris的速度比ClickHouse快2~3倍;针对大型维度表,Doris的速度要快十倍以上;针对大于1亿行的维度表,ClickHouse抛出了OOM错误,而Doris可以正常运行。主表(250亿行):全连接查询:Doris在所有维度表的全连接查询中性能优于ClickHouse。ClickHouse在维度表大于5000万行的情况下抛出了OOM错误。过滤连接查询:过滤器从主表中筛选出5.7亿行。Doris在几秒钟内做出响应,ClickHouse在几分钟内完成,在连接大型维度表时出现了崩溃。主表(960亿行):Doris在所有查询中都给出了比较快的性能,而ClickHouse无法执行所有查询。在CPU和内存消耗方面,Apache Doris在所有大小的连接查询中都确保了集群负载的稳定性。原文标题:Migrating From ClickHouse to Apache Doris: What Happened?,作者:Frank Z
- 最近更新
- 2025-11-05 06:27:22从零开始学习机械师DOS装系统教程(掌握DOS装系统,轻松解决电脑问题)
- 2025-11-05 06:27:22MySQL存储秘密揭示:CHAR vs.VARCHAR,解锁定长神器的终极选择指南!
- 2025-11-05 06:27:22乘客在航班上架设恶意WiFi热点面临长达23年刑期
- 2025-11-05 06:27:22紧急!Spring Boot安全漏洞
- 2025-11-05 06:27:22腾讯会议电脑使用技巧教程(掌握腾讯会议,提升工作效率的关键技巧)
- 2025-11-05 06:27:22Win7/Win8.1/Win10的UAC对话框“是”点不了怎么办?
- 2025-11-05 06:27:22灾难恢复与从勒索软件攻击中恢复:为什么CISO需要同时规划这两者
- 2025-11-05 06:27:22使用示例和应用程序全面了解高效数据管理的Golang MySQL数据库
- 热门排行
- 2025-11-05 06:27:22电脑蓝屏错误代码的解析与处理方法(探索蓝屏错误代码背后的故事,帮助你解决电脑问题)
- 2025-11-05 06:27:22悬崖勒马,微软计划“隐藏”Windows回忆功能
- 2025-11-05 06:27:22三种方法助你开关Windows 10中的飞行模式
- 2025-11-05 06:27:22“最危险联网设备资产”榜单发布
- 2025-11-05 06:27:22解决电脑Java平台错误的有效方法(探索如何应对和修复常见的电脑Java平台错误)
- 2025-11-05 06:27:22什么样的安全事件响应管理系统更好用?10项功能不可或缺
- 2025-11-05 06:27:22Linux/Unix桌面趣事:让桌面下雪
- 2025-11-05 06:27:22如何在Linux下安装复古终端